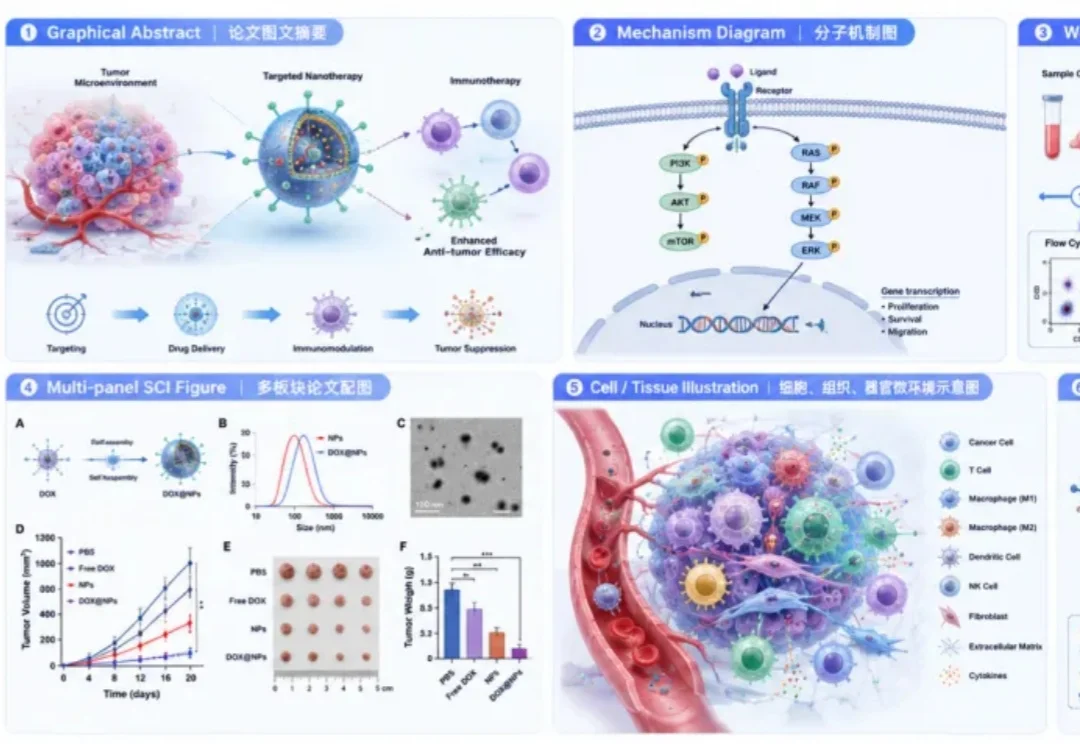
SCI 论文配图 Prompt 怎么写?这篇直接抄
SCI 论文配图 Prompt 怎么写?这篇直接抄做科研的人应该都懂,论文配图真的很耗时间。
来自主题: AI技术研报
5413 点击 2026-06-23 15:03
 搜索
搜索
做科研的人应该都懂,论文配图真的很耗时间。
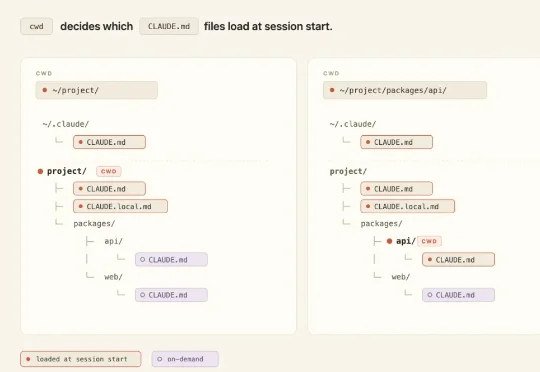
在常规的对话外,Claude Code(也可以是 Codex)其实还提供了一些别样的控制(或者说:上下文注入)方法,比如:CLAUDE.md、Rules、Skills、Subagents、Hooks、Output Styles、以及 System Prompt Append

一开始,忽悠 AI 挺简单。
AI 正在学着操作电脑。由清华大学计算机系博士团队创立的非十科技,最近发布了一款桌面 Agent 产品 ———Agivar。与多数产品试图优化 Prompt 不同,它选择从另一个方向切入:让 AI 主动学习用户的工作流程。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。

其实大概半年前,我就有这个需求了。那阵子我也注意到,阿里、字节这些平台都各自出了提示词优化器。但它们都得专门跑到对应的网站上去用,对我来说不够顺手。所以这回干脆借着深度复盘了 Anthropic 的 Prompt 讲座,用 Codex vibe coding 了一个全局提示词优化器。

如今想写出一篇结构严密、用词专业的文章已经不算难事,只需要敲几个 prompt 生成式 AI 就能瞬间给你一篇成千上万字的文章。布鲁金斯学会去年的一项调查显示,拥有学士学位的成年人中有 35% 的人在工作中使用 AI 来撰写或编辑文档。
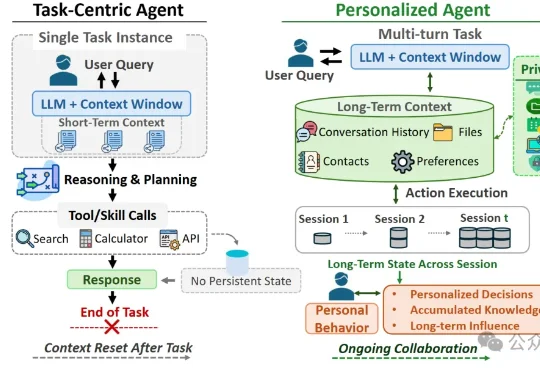
日常聊天可能在不经意间污染个性化Agent的长期记忆,使其在未来任务中偏离用户真实意图。研究人员通过ULSPB基准测试发现,即使无恶意提示,日常对话也可能改变Agent的安全边界。
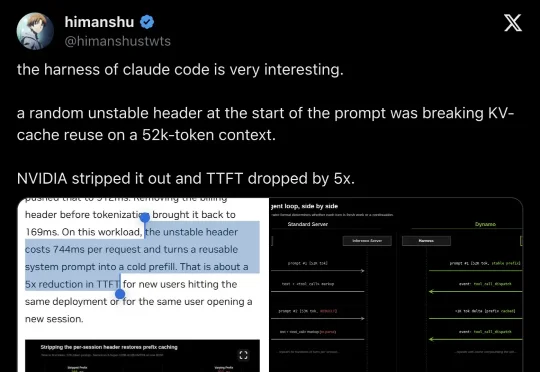
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `